Querying Documents
You can attach various documents to your function by using the .document method
Syntax
The basic syntax for querying documents in llm-functions-ts is as follows: Let's say you want to create a function that takes an invoice as pdf and returns the line items:
export const invoiceFromPdf = llmFunction
.name("Invoice from PDF")
.description("Takes an invoice and returns the line items")
.document({ type: "pdf", name: "invoice.pdf" })
.output(
z.object({
subtotal: z.number().nullable(),
taxes: z.array(
z.object({ name: z.string().nullable(), amount: z.number().nullable() })
),
total: z.number().nullable(),
lineItems: z.array(
z.object({
description: z.string().nullable(),
date: z.string().nullable(),
activity: z.string().nullable(),
item_amount: z.number().nullable(),
item_amount_total: z.number().nullable(),
quantity: z.number().default(1).nullable(),
tax: z
.string()
.nullable()
.describe(
"Name of the tax. Can be GST/HST, Nola tax etc. It is not the tax amount"
),
})
),
})
)
.create();We don't provide any instructions here. GPT is smart enough to infer the data from the zod schema!
The invoiceFromPdf has the following type signature
const invoiceFromPdf: (args: {
documents: [Buffer | string];
}) => Promise<{
subtotal: number | null;
taxes: {
name: string | null;
amount: number | null;
}[];
total: number | null;
lineItems: {
date: string | null;
description: string | null;
... 4 more ...;
tax: string | null;
}[];
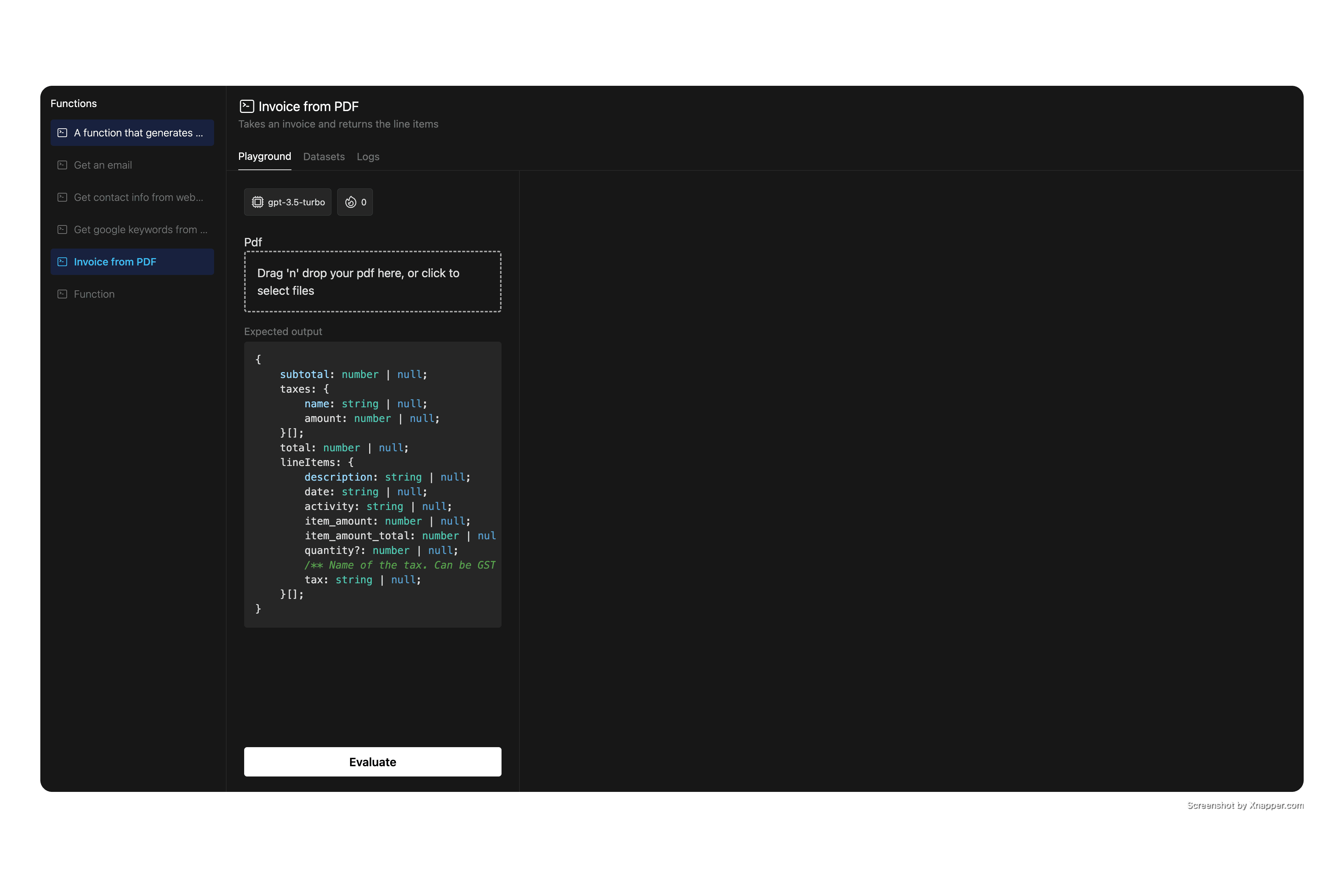
}>A PDF can be passed to the function as a buffer or a url string. Internally, the function will automatically convert the pdf to text or even fetch the pdf from the url if a url is provided. This function will generate this UI
(TODO: REPLACE THIS UI WITH A GIF)
Large documents
LLMs have a limited context length. This means that you can only pass a limited amount of data with each call. This is a problem if you want to give LLM a large document. It simply cannot fit in the context. The solution is to split the document up into small chunks and only send the relvant chunk to the LLM.
llm-functions-ts automatically takes care of chunking and choosing the relevant chunk to include in the LLM call.
To understand how this works in detail, take a look at the embeddings page.
Here's a quick overview on how llm-concepts-ts handles large documents:
- The document is split into chunks and each chunk is embedded into a vector
- When the LLM is called, we get the embedding of the user query
- We find the chunk that is semantically closest to the user query
- This chunk is passed to the LLM call
llm-functions-ts tries it's best to find the best chunk to pass to the LLM.
In cases you want to specify exactly how to find the chunk, .document takes an additional argument chunkingQuery.
Check out the Scraping contact information recepie as an example.
Types of Documents
.document({ type: "pdf" })URL
.document({ type: "url" })Text
.document({ type: "text" })